YARN Lost Node显示异常
先说现象,在yarn的web页面,Lost Nodes指标显示的数据异常,如下:
我的集群一共有5台节点,这里显示有一台节点为Lost Nodes,但依然有5台Active Nodes,细心观察发现或有某个节点即存在Active Nodes中也存在Lost Nodes中,只是端口不一样。
这种情况如何解决呢?
在yarn-site.xml中添加yarn.nodemanager.address配置项,如下:
1 | <property> |
需要重启集群,让参数生效。
现在你可以去修改你集群的配置,是不是瞬间心情愉快了很多,那是不是可以继续读下去,看下我们如何解决这种问题。
搜索
首先利用搜索引擎,看下是否有没有前人帮你埋坑。(当你搜到这篇blog,说明你已经具有了这种能力)
镇定
没有前人埋坑,怎么办?有的同学就慌了,解决不了了,怎么办?先重启解决吧。。。
重启是可以解决遇到的问题,但我们不能遇到问题就重启。在重启之前,我们也要进行一些评估,评估下这个问题是不是很严重,是不是需要立马解决。
目前我们遇到的这个问题很明显不是那种需要立马重启服务来解决的问题,那我们应该怎么解决这个问题呢?最好的答案就是看源码。
一个项目代码那么多,在你不熟悉每一行代码的时候如何快速定位关键代码并找到问题所在呢?
我认为很简单,就两步,首先全文检索找到表象,然后逆向跟踪代码并找到答案。
定位关键代码入口
全文检索关键字Lost Nodes,结果如下: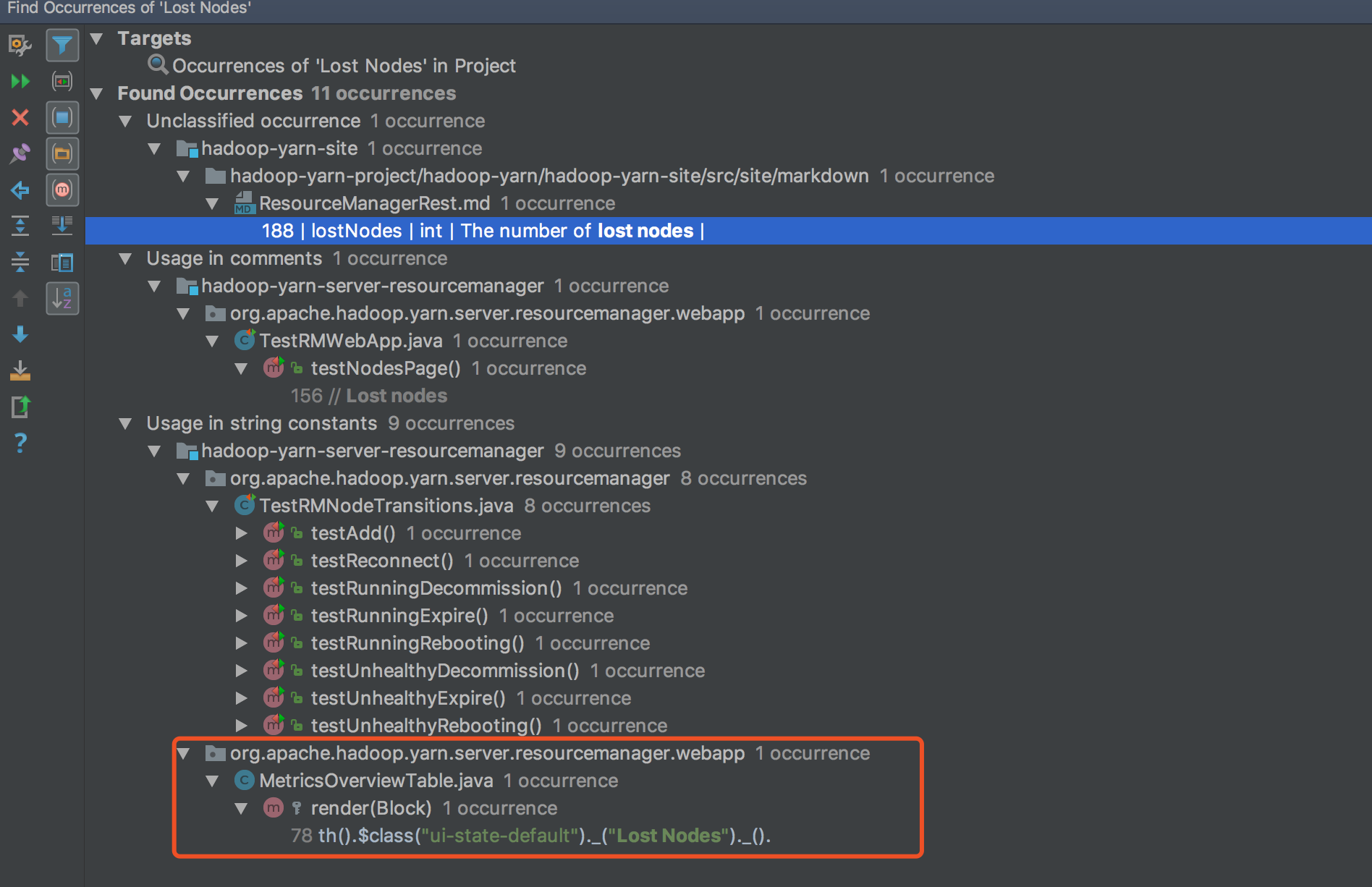
从结果中我们可以根据经验定位到关键入口应该在webapp包中,点击进MetricsOverviewTable中的相关代码位置
代码如下:
1 | th().$class("ui-state-default")._("Lost Nodes")._() |
是不是找到了,clusterMetrics是一个ClusterMetricsInfo的对象。
ClusterMetricsInfo存储了整个集群的metrics信息,其中有个属性lostNodes,然后根据这个属性跟踪到ClusterMetrics.numLostNMs,该属性存在三个方法,如下:
1 | //Lost NMs |
代码跟到这里,你就可以随所欲为了。。。
LostNode显示异常,不是增加的时候有问题就是减少的时候有问题,无非这两种情况,我们先看下incr的逻辑
Lost Node incr
根据incrNumLostNMs方法我们反跟踪到NM的状态机相关的代码,这里我按照顺序的逻辑来梳理代码
先看下一个正常RUNNING的节点是怎么变为Lost Node节点的
1 | .addTransition(NodeState.RUNNING, NodeState.LOST, |
NM状态的变化是由RMNodeEventType.EXPIRE事件触发的,NM5分钟没有与RM进行心跳会触发这个事件,这个时间是在代码里写死的public static final int DEFAULT_EXPIRE = 5*60*1000;//5 mins。
我们看下DeactivateNodeTransition这个handle的实现:
1 | public void transition(RMNodeImpl rmNode, RMNodeEvent event) { |
metrics信息是在updateMetricsForDeactivatedNode中增加的,查看其具体逻辑没有什么异常逻辑,就是简单的根据具体的状态对其进行incr和decr。
这里我们需要注意在更新metrics之前的一个put操作,这里将当前节点put到一个inactive队列中,LostNode的具体节点信息存储在这里,这里会不会有问题呢?
inactive是ConcurrentMap<String, RMNode> inactiveNodes = new ConcurrentHashMap<String, RMNode>()是一个线程安全的,看下这里的kv到底存的是什么,查其源码可以看出这里key是主机host,不与端口绑定,重启NM时可以从inactive中取出对应的host。
incr的逻辑并没有发现什么问题,那继续看下decr相关的代码
Lost Node decr
根据decrNumLostNMs方法我们反跟踪到NM在启动的时候会触发这部分代码,大体流程是RMNodeEventType.STARTED事件触发,由AddNodeTransition进行捕获处理。
1 | // 事件触发状态转换 |
从上面的代码得知,新启动一个节点回去inactive队列中check下是否存在,存在则更新下Lost Nodes的metrics计数信息,不存在则不更新Lost Nodes metrics的计数信息。
看到这里是不是感觉incr和decr的逻辑都正常,不存在Lost Nodes的metrics更新异常的问题,但是根据故障的想象仔细分析会发现肯定是新启动的NM没有从Lost Nodes中正常减少,那么什么情况会不正常呢?
新启动一个节点需要去inactive中check下当前节点是否存在,那么如果当前节点之前启动的信息还没有放入inactive那这次新启动时就无法check成功,那就当成一个新的节点启动了。因为从incr的代码中分析可以得知NM在
RMNodeEventType.EXPIRE事件之后才会放入inactive中,这个事件需要超时5分钟,这个时间差就导致了Active Nodes与Lost Nodes总数与集群的规模不匹配的原因,我们验证下,把一个节点停掉然后立马启动,会发现Active Nodes增加了一个,待5分钟之后,Lost Nodes中增加一个,Active Nodes减少一个,此时Active Nodes正常,但Lost Nodes显示异常,与开篇的现象一致。
解决问题
明白了故障出现的原因,就离解决方案不远了。这个显示异常其实是因为每个NM启动的时候端口是随机的,如果某个NM停止和启动间隔时间较短(小于5分钟),则之前启动的NM进程在超时之后状态转换为Lost状态,但当前host上的新NM进程已经启动,无法触发Lost的更新操作。
关键环节出现在检查超时这里,超时是通过NM与RM之间的心跳来维护的,心跳是由host+port来识别的,把NM对应的port固定就可以解决这个问题了。
那么我们就找下这个端口是在哪生成的。
我们从decr处的代码作为入口进行反跟踪。AddNodeTransition.transition中inactive的key是从rmNode.nodeId.getHost()中得到的,rmNode是RMNodeImpl类的一个实例,我们来看下RMNodeImpl中nodeId属性是如何赋值的,发现是在构造函数中赋值的,如下:
1 | public RMNodeImpl(NodeId nodeId, RMContext context, String hostName, |
那这个对象又是在哪实例化的呢?继续跟踪到ResourceTrackerService.registerNodeManager方法,发现port信息是从request请求中取的,request是在NodeStatusUpdaterImpl.registerWithRM实例化,而实例化使用的nodeId是NMContext的一个属性且通过setNodeId进行赋值的,这个赋值操作发生在ContainerManagerImpl.serviceStart中,代码如下:
1 | protected void serviceStart() throws Exception { |
看上面的代码发生nodeId是通过connectAddress实例化的,而connectAddress又是initialAddress得到的,initialAddress就是我们要找的终极目标。
这里的主要是两个变量YarnConfiguration.NM_BIND_HOST和YarnConfiguration.NM_ADDRESS对应的配置项是yarn.nodemanager.bind-host和yarn.nodemanager.address。
显而易见yarn.nodemanager.address的默认值是${yarn.nodemanager.hostname}:0控制了NM的端口,在这里指定端口来固定NM的心跳端口,在NM重启的时候可以继续之前的心跳端口,来避免重启的时候导致Lost Nodes显示异常。
事后诸葛
其实如果你熟悉Hadoop的状态机的话,很容易直接定位到Lost Nodes的变化是在NM状态变化的时候触发的,这就直接定位到关键类RMNodeImpl
 wechat
wechat
