Append/Hflush/Read设计文档
本篇是一篇译文,主要是翻译下Append/Hflush/Read Design。hdfs的write一直看不太懂,想翻译下此设计文档,希望能有更深入的理解。
Replica/Block 状态
Block在NameNode和DataNode中有不同的称呼,在NameNode中为block,在DataNode中为Replica。通常说的block的副本数是3,指的就是dn中Replica为3。
Replica状态
Finalized:
finalized Replica已经完成了写入操作。不会再有新的数据写入,除非此Replica被再次打开或者被追加。
finalized Replica的数据和meta数据是匹配的。
当前block id的所有Replica有相同的数据大小。
但是finalized Replica的GS(generation stamp)不是一直不变的,GS可能因为一次错误的recovery而导致其发生变化。
RBW(Replica Being Written):
创建Replica或者追加Replica时,Replica的状态为RBW。
数据写入RBW状态的Replica。其RBW Replica总是一个未关闭文件的最后一个block的Replica。
同一个block id的RBW状态的Replica的长度不固定。
RBW状态的Replica在磁盘中的数据与meta数据不匹配,也就是说还有一部分数据在内存中没有flush到磁盘。
RBW状态的Replica中的所有数据对readers并不都是不可见的,只有接受到queue ack的packet才是可见的。
如果发生故障,RBW状态的Replica中的数据是需要保护的。
RWR(Replica Waiting to be Recovered):
DataNode挂掉或者重启时,所有RBW状态的Replica变为RWR状态。
RWR状态的Replica不会在pipeline中存在,因此RWR Replica也不能写入数据。
RWR状态下的replica将会变成过期,或者*当client死了之后,RWR将出现在租约恢复的过程中(将RBW状态的Replica转为RWR)*。
RUR(Replica Under Recovery):
租约恢复会触发Replica恢复(or Block Recovery),此时,任何一个非TEMPORARY状态的replica都有可能转换为RUR状态。
租约恢复会触发Block恢复,此时Replica的状态转为RUR,那么RWR是在哪租约恢复中哪里出现??
TEMPORARY:
在block复制(由replication monitor或者balancer引起的block复制操作)中会出现temporary状态的replica。
此状态下的replica与RBW状态类似,只是该状态下的数据是不可见的。
如果block复制失败,TEMPORARY状态下的replica会被删除。
在DataNode磁盘中(也就是存放block的dn磁盘中),每个data目录都有三个子目录,分别为current、tmp和rbw。其中current中存放finalized replicas,tmp目录存放temporary replicas,rbw目录存放rbw、rwr和rur replicas。
当replica是由于replica复制或者balance而创建的,则将此replica放入temp目录。一旦一个replica完成,也就是finalized,则将其移动到current目录中。当DataNode重启时,tmp目录下的replicas被删除,rbw目录下的replicas被做为rwr状态进行加载(rbw目录下存放着rbw、rwr、rur,rur也转换为rwr???转换为rwr之后怎么办呢??),在current目录下的replicas被做为finalized状态进行加载。
在DataNode升级过程中,在current和rbw目录下的所有replicas将被保存在一个快照中。
Block状态
Block在NameNode中的状态为:
UnderConstruction:
新建一个block或者打开已存在的block来追加,此时block为UnderConstruction状态。
UnderConstruction状态的block可以写入数据。通常是一个未关闭文件的最后一个block。
由于此状态下的block可以写入数据,则UnderConstruction block的长度和GS是不固定的。
UnderConstruction block中的数据并不是完全可见的。
UnderConstruction block会记录write pipeline的位置,如果client挂了,也会记录rwr replicas的位置。(A block underconstruction keep strack of its write pipeline(i.e.,locations of valid rbw replicas) and the locations of its rwr replicas if the client dies)
对应Replica的状态为RBW
UnderRecovery:
当一个文件的租约超期之后,如果此文件的最后一个block是UnderConstruction状态,当block恢复开始时,UnderConstruction变为UnderRecovery状态。
对应Replica的状态为RUR
Commited:
Committed block的长度和GS是不变的,除非该block被再次打开来追加。但是DataNode还没有上报这样的Replica,导致NameNode中找不到与之匹配的finalized replica,此时block被称为Committed状态。
为了响应读请求,Committed block依然要保留rbw replicas的地址。也要记录finalized replicas的GS和长度。
当client要求nn给未关闭的文件增加一个block或者关闭此文件时,一个UnderConstruction block变为Committed。
如果一个文件的最后一个block或者倒数第二个block是COMMITTED状态,则该文件不能被关闭,client必须进行重试。
Add Block and close will be extended to include the last block’s GS and length.
Complete:
Complete block的长度和GS是不变的,并且NameNode已经发现当前block的finalized replica能够和GS/len匹配。
Complete block只保存finalized replicas的位置。
只有当一个文件的所有block都是Complete时,才能关闭。
对应Replica的状态为Finalized
和Replica的状态不同,block的状态不会在固化到磁盘。当NameNode重启时,未关闭文件的最后一个block的状态为UnderConstruction进行加载,剩下的block都为Complete状态。
更多的细节包括Replica和Block状态的转换图都将在后面的章节中介绍。
疑惑Replica与Block的状态是怎么交互的?????
Write/Hflush
write pipeline
HDFS文件是由多个block组成。block是通过write pipeline将数据写入的。Bytes数据以packet为单位被推送到pipeline中。如果不发生error,block的构成会经过3个阶段。如图所示。
此pipeline包含3个DataNode(DN0、DN1和DN2)和一个由5个packet组成的block。
图中的粗线表示packet,虚线表示ack messages,细线表示控制信息(setup/close)。
t0-t1是pipeline的setup阶段。t1-t2是data streaming阶段(t1发送第一个packet,t2是接收最后一个packet的ack),在数据传输中需要注意的是packet3之所以要等到接收到packet2的ack之后才发送是因为packet2调用了hflush。t2-t3是pipeline的close阶段。
下面详细介绍下着3个阶段:
setup:
client沿着pipeline的下游dn发送了一个Write_Block请求。当最后一个dn接收到这个请求,会沿着pipeline的上游dn发送一个ack给client。此时,pipeline中dn的网络连接就被建立,并且每个dn都创建或者打开一个Replica,等待写入数据。
data streaming
数据首先被缓存在client端的buf中,当buf写满之后写入packet中。一个packet写满之后,被发送到pipeline中。下一个packet在接收到之前packet的ack之前就可以发送到pipeline中。未完成packet(未发送和未接收到ack的packet统称未完成的packet,原文是outstanding packets)的个数是由client控制的,代码中是80(是dataQueue和ackQueue中packet的和),超过了限制则阻塞。
如果代码中明确调用hflush,会将当前packet发送到pipeline中(是把packet发送到dataQueue等待DataStreamer来取还是直接发送到pipeline中??),无论此packet是否已经写满。Hflush是一个同步操作,在接收到此packet的ack之前,不能写入任何数据。
close(finalize a block and shutdown pipeline)
当client收到所有packet的ack之后,发送一个关闭请求。
这样保证了如果在data streaming失败了,恢复操作没有必要去处理一些情况,如一些Replicas已经Finalized和一些Replica并没有完整的数据。(This ensures that if data streaming fails, the recovery does not need to handle the case that some replicas have been finalized and some do not have all the data)
packet在某个DN中是流程

对于每个packet,pipeline中的dn会做3件事:
- Stream data
a. 从上游的dn或者client接收数据
b. 如果下游有dn则向下游发送数据 - 将data或者crc写入block文件或者mate文件
- Stream ack
a. 如果下游有dn则接收下游dn发送的ack
b. 向上游dn或者client发送ack
需要注意的是上面的数字并不代表这三件事的执行顺序。
Stream ack(3)会在Steam data(1)之后执行,但是理论上write data to disk(2)可以发生在1.a之后的任何时间里。代码中在执行1.b之后并且接收到下个packet之前去执行write data to disk(2)
pipeline中的DataNode有两个线程。data线程负责data stream和disk writing。对于每个packet,data线程按照顺序执行1.a、1.b和2。packet被flush到磁盘之后,可以从内存中移除。ack线程负责ack streaming。对于每个packet,ack线程按照执行3.a和3.b。由于data线程和ack线程是同时执行的,因此无法保证(2)和(3)的执行顺序。packet的ack可能会在写入磁盘之前发送。
算法在写性能、数据持久性和算法的简单性做了个权衡。
1、尽快的将数据写入磁盘而不是等待接收到ack之后,能够提升数据的持久性,防止数据丢失。
2、并发的执行data线程和ack线程
3、在pipeline的内存中最多只存在一个packet,使buffer管理很简单。
(pipeline是怎么保证内存最多只有一个packet的???写入磁盘的packet就从内存删除???)
一致性
- client从RBW Replica中读数据时,DataNode不会将接收到的所有数据都对client可见。
- RBW Replica维护着两个计数器:
1、BA: 接收到下游ack的bytes数。这些数据对client是可见的。也被称为Replica的可见长度。
2、BR: block已经接收到的bytes数,包括写入磁盘的和在dn内存中的数据。 - 假设开始在pipeline中的所有DataNode中RBW Replica的两个计数器(BA, BR)=(a, a)。则当client将一个大小为b bytes的packet发送到pipeline中,在client接收到packet的ack之前没有别的packet发送到pipeline中。
1、某个DN执行完1.a之后,(BA, BR)变为(a, a+b)
2、某个DN执行完3.a之后,(BA, BR)变为(a+b, a+b)
3、当client成功接收packet的ack之后,pipeline中所有dns的RBW Replica的计数器变为(BA, BR)变为(a+b, a+b) - pipeline中有N个DataNode(DN0、DN1、…DNn),DN0是pipeline中的第一个,离client最近,则有下面的特性:
在任何给定的时间t,
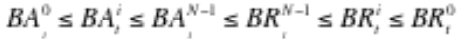
这个特性保证了一旦数据变为可见的,则pipeline中所有的dn都有此数据。(只要接收到ack的packet就是可见的?一旦数据是可见的,保证所有的dn都有此数据,但不保证该数据在所有的dn上都是可见的??是这样理解吗??还是说只有client接收到ack之后数据才是可见的??我感觉是前者。随后验证) - 假设BSc表示client在时间点t发送到pipeline中的数据长度,BAc是client接收到ack的数据长度。则上面的公式变为如下:
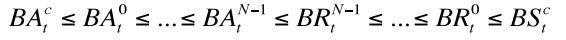
Read
读一个未关闭的文件时,存在的挑战是如果最后一个block是UnderConstruction,那么如果保证一致性。解决思路是保证在DNi上读到的数据也能在DNj上读取,尽管BAi>BAj。
第一种解决方案:
- 当client读一个UnderConstruction block时,先向DN发送一个请求得到这个Replica的BA
- 如果要读的长度超过了UnderConstruction block的BA,那么抛出一个EOFException异常
- 只有当read请求的起始偏移地址小于最后一个block的可见长度时(是起始位置小于可见长度,即off小于BA。那么只要off大于BA,即使len小于BR,也不会发送给DN??),才会发送给DN。当DN收到一个read请求,读取的长度小于BR,则返回此区间的数据。
- 假设read请求是一个三元组(blck, off, len),其中blck包含blockId和GS,off是读取的起始位置,len要读取数据的长度
- 如果DN有个Replica的GS等于blck的GS或者比blck的GS新,则可以响应当前read请求。
- 假设client从DNj上得到了block的length,则off和len的和必须小于等于BAj。
- 假设read请求发送给了DNi(能发送个DNi,则off一定小于BAi),DNi上的一个Replica的状态是(BAi, BRi),则
1、如果off+len<=BAi,DNi能从off处发送len长度的bytes给client
2、如果off+len>BAi,并且off+len<=BAj(*由上一条假设得知*),BAj>=BAi,则DNi在pipeline中一定是DNj的上游,也就是离client的距离比DNj要近。则BRi>=BRj>=BAj。BRi>BAj,所以BRi>off+len。也就是说DNi有client想要读取的数据,则DNi发送数据给client
3、off+len一定不能比BRi大,如果发送了这种情况,DN记录下error并拒绝这次请求。 - 如果正在响应read请求的DNi挂掉了,client能在该block的其它Replica所在的DN中任意切换。
- 这个解决方案比较简单,但是需要重新打开一个文件去取数据,因为最后一个block的可见长度是在client read之前从DN上得到的(也就是说client要先跟从一个DN上得到可见数据的长度,然后再去打开一个文件去读数),而且client读取的数据的长度不能超过最后一个block的长度。
概括下这种方案的读取流程:
读操作分为两次请求:
第一次向block的Replica所在的某一个DN(该DN记为DNi)发送一个请求,得到block的可见长度BAi,如果off+len大于BAi,则抛出EOFException;
第二次请求是向Replica所在的某个DN发送读请求,发送时要判断off是否小于该DN的BA,只有小于BA才向该DN发送读请求。(发送给DN,DN是否响应,其判断标准为DN有个Replica的GS等于blck的GS或者比blck的GS新,则可以响应当前read请求)
第二种解决方案
- 此种方案是让client控制一致性,DN只负责发送数据。
- 假设read请求是一个三元组(blck, off, len),其中blck包含blockId和GS,off是读取的起始位置,len要读取数据的长度
- 如果DN有个Replica的GS等于blck的GS或者比blck的GS新,则可以响应当前read请求。
- 假设DNi中某个Replica的状态是(BAi, BRi),则DNi能发送的数据为[off, min(off+len, BRi)],并将BAi一起发送给client
- client接收这些数据,并去查找当前Replica最大的BA
- 如果DNi读失败,client能去任何一台包含此Replica的DN上读取
- 如何保证一致性的呢?
假设有一个由N个DN组成的pipeline,DN0是pipeline中的第一个。
假设client在时间t能够提供给application的长度是BRc,则
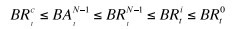
因此无论从那个DN上读取数据,DN都能够满足。 - 此方法需要改变下读协议,由于client端要控制读的一致性则会变的较复杂。但是此方法不用请求再次打开一个文件去读数据。
代码中应该用的是第一种,有时间验证下
Append
Append API
- client向NN发送一个append请求
- NN首先确认此文件已被关闭,然后检查这个文件的最后一个block,
如果此block没有写满并且没有Replica,则append操作失败。否则将block改为UnderConstruction状态。
如果最后一个block写满了,则NN分配一个新的block作为最后一个block。
如果最后一个block没有写满,NN改变这个block的状态为UnderConstruction,并用该block的Finalized Replicas来初始化pipeline(If the last block is not full, NN changes this block to be an underconstruction block, with its finalized replicas as its initial pipeline)
返回blockId、GS、length和locations。如果最后一个block未满,也需要返回一个新的GS。 - 如果最后一个block不满,则为append建立一个pipeline。否则为create建立一个pipeline。
- 如果最后一个block最后一个chunk没有达到chunk边界,则读取最后一部分的crc chunk,读取它是为了重写计算chunksum
- 剩下的和正常写的流程一样
持久化(Durability)
- NN保证包含append之前数据的Complete block的副本数满足该文件的副本数。
- 包含append之前数据的UnderConstruction block的持久化在此版本中没设计
故障处理
pipeline Recovery
当一个block是UnderConstruction状态时,可能在stage1、stage2和stage3发生错误。stage1是指pipeline setup,stage2是指data streaming,stage3是指pipeline close。pipeline recovery处理pipeline中的DNs发生的error。
stage1发生故障
在pipeline setup时,某个DN发生了故障,这个DN发送一个故障的ack到上游DN之后,关闭block文件和所有的tcp/ip连接。一旦client检测到这个故障,client会根据建立pipeline的目的而进行不同的操作:
- 如果新建一个pipeline是为了创建一个新block,则client只是放弃这个block,重新向NN申请一个新的block。然后为这个新的block建立pipeline
- 如果新建一个pipeline是为了append一个block,则client会用*剩下的DNs(不添加新的DN到pipeline中??)*重建一个pipeline并更新block的GS。
访问token错误在pipeline setup中是一个特殊的故障。如果由于access token过期而导致pipeline setup失败时,client会继续用之前的DNs重建pipeline。
stage2发生故障
- DN的故障可能发生在1.a、1.b、2、3.a和3.b中的任何一个阶段。无论何阶段,当故障发生时,发生故障的DN会退出pipeline(关闭所有的tcp/ip连接,如果故障不是发生在3.a和3.b则将内存中的数据写入磁盘,关闭磁盘上的文件)。
- 当client检测到故障时,停止发送数据到pipeline
- client利用剩下的DNs重构一个pipeline,该block的所有Replica都会产生一个新的GS
- client从BAc处重新发送数据,此时GS已经更新。这里有个可以优化的地方就是client从min(BRi, i是pipeline中DN的索引)处重新发送数据。
- 当DN接收到一个packet时,如果当前DN上已经存在,则data stream直接将其packet发送到下游而不再次写入磁盘。
此recovery策略有个很好的特性:只要在old pipeline中数据是可见的,则在重新建立的pipeline中依然是可见的,即使在old pipeline中存放最大长度BA的DN挂掉了。这是因为在pipeline recovery中不会减少任何DN的BA和BR。
stage3发生故障
client检测到故障,会利用剩下的DNs重建一个pipeline。每个DN会更新block的GS和将未finalized的replica变为finalized。发送一个ack之后关闭所有的网络连接。
DataNode Restart
- DataNode重启时,会将data目录下rbw子目录下的所有replica的状态变为RWR状态加载到内存,这些Replica的长度是有crc记录的最大值。
- RWR Replica是不可见的,也不会出现在pipeline recovery中,也是不可写的(只有在pipeline中的replica才是可写的)。
- RWR Replica的client如果存在,则该Replica可能会过时而被NN删掉,如果client不存在,则通过lease recovery将状态变为finalized。
NameNode Restart
- NameNode上不会将block的状态固化到磁盘。因此当NN重启时,需要重新存储block的状态。对于未关闭文件的最后一个block不管该block之前是什么状态都变为UnderConstruction状态,其它的block都是Complete状态。
- 要求每个DN注册并发送block report。block report中包括除了TEMPORARY状态的所有状态的Replica(finalized、rbw、rwr、rur、)。
- 当NameNode接收到最少一个副本的Complete状态的block和UnderConstruction状态的block的个数达到之前设置的阈值时,才退出safemode模式。(NameNode does exit safemode unless the number of complete and under construction blocks that have received at least one replica reaches the pre-defined threshold)
Lease Recovery
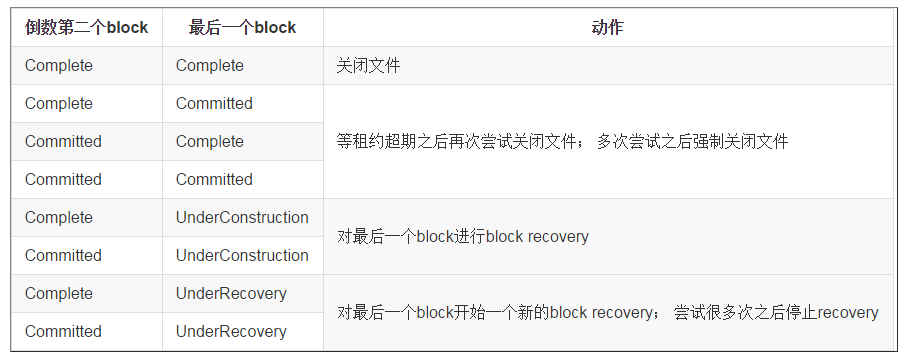
当问及的租约超期之后,NN要为客户端关闭这个文件。这里有两个问题:(1)并行控制,要是在pipeline setup、data steam、pipeline close或者pipeline recovery阶段中,并且client依然存活的时候进行lease recovery会怎样?如果存在多个并行的lease recovery怎么办?(2)一致性保证,当最后一个block是UnderConstruction状态时,其block的所有Replica需要保持一致的状态,也就是说所有的Replica在磁盘上应该记录相同的长度和一样的GS。
- NN续约时(NN renews lease, 是不是翻译成NN恢复租约时,更加合适),改变这个文件的租约所有者为dfs并将操作记录在editlog。因此如果client依然活着,任何一个与写相关的请求如生成一个新的GS、增加一个新的block或者关闭这个文件,将被拒绝。之所以被拒绝是因为client此时已经不再拥有此文件的lease。这就阻止了client并发的改变一个未关闭的文件。
- NN检查这个文件的最后一个block状态。其它的block应该是Complete状态。下表展示了所有可能的组合和相应组合所采取了动作:
Block Recovery
NN选择从Replica所在的DNs中选择一个primary DataNode(PD)作为NN的代理来执行block recovery。如果block没有Replicas则放弃block recovery。
NN得到一个新GS。GS用来标识这个block在recovery成功之后的版本。Block recovery改变最后一个block的状态,如果它是UnderConstruction,则改为UnderRecovery状态(not RUR)。UnderRecovery block由唯一的recovery id标识和新的GS。PD和NN的任何一次通信,都需要匹配recovery id。这就是怎样并发处理block recovery的。最基础的规则就是最近要提交的recovery的优先级高于之前提交的。
随后NN要求PD recovery block。NN发送给PD新的GS、block id和所有Replica的locations(包括finalized replica、RBW replica和RWB replica)。
PD执行block recovery:
a. PD要求Replica存在的每一个DN去执行replica recovery。
i. PD将recovery id、block id和GS发送给每个DN
ii. DN检查各自Replica的状态:1、 检查是否存在:如果DN没有这个replica,或者这个replica的GS比请求中的GS要老,更或者是比recovery id要新,则抛出ReplicaNotExistsException 2、检查是否停止写入:如果一个replica正在写入和一个正在写入的线程,则中断写线程,等待写线程退出。如果写线程正在接受packet时被中断,则停止写线程并放弃这个写入一半的packet。在线程退出之前,确认磁盘上记录的长度与BR相同,然后关闭block文件和crc文件。*这样控制了client write和block recovery在DNs上的并发*。Block recovery抢占client write,导致pipeline失败。随后的pipeline recovery会失败,因为dfs client从NN得到一个UnderRecovery状态block的GS。 3、停止之前的block recovery:当某个Replica已经是RUR状态时,如果此Replica的recovery id大于等于刚收到此Replica的recovery id,则抛出 RecoveryInProgressException。如果刚收到的GS大,则表示RUR replica的recovery id设置为刚收到的recovery id。 4、状态改变:将Replica的状态变为RUR。设置recovery id为一个新的recovery id和原来状态的一个引用(Set its recovery id to be the new recovery id and a reference to its old state.)。任何一次PD和它的通信都需要匹配recovery id。*Note3和4在DNs的block recovery并发的问题*。最后一个recovery总是优先于之前的recovery,并且没有两个recovery会有所交叉。 5、检查crc:对block文件进行一次crc检查。如果Replica的状态是finalized或者RBW时,crc不匹配则抛出CorruptedReplicaException 。然而如果Replica的状态是RWR时,对block文件进行裁剪,将不匹配的部分减掉,保留上次匹配的长度。iii. 如果没有任何异常抛出,每个DN将Replica的状态(Replica id、GS、on-disk len、pre-recovery state)返回给PD。
b. 从DN收到响应之后,PD来决定block的长度。
i. 如果有一个DN抛出RecoveryInProgressException,则PD放弃block recovery。
ii. 如果所有的DN抛出一个exception(所有的DN抛出的exception必须相同还是???),则放弃block recovery。
iii. 如果NN接收到的所有最大Replica的长度为0,则NN删除这个block
iv. 否则,检查长度非0的Replica返回的状态。下表是两个Replica的可能组合情况:

c. Recovery Replica的长度设置参考b.iv
i. PD要求每个DN去恢复Replica,由PD发送block id、GS和长度
ii. 如果DN中不存在RUR状态的Replica或者Recovery id和新的GS不匹配,则失败
iii. 否则DN改变这个Replica的GS为新的GS。随后在内存中更新此Replica的长度为新的长度,裁剪这个block file(磁盘中的文件)的长度并改变crc file(may casuse truncation and/or modification of last 4 crcbytes)。如果该Replica不是Finalized状态则变为Finalized状态。此时Replica Recovery成功
d. PD检查c的结果。
如果没有DN成功,则block recovery失败。
如果一些成功一些失败,PD从NN处得到一个新的GS,让成功的DN重复block recovery。
如果所有的DN都成功了,PD将新的GS和长度告知NN。
NN finalizes the block,并且如果这个文件的所有block都是Complete状态,则关闭文件。在超过了尝试关闭文件的次数之后,NN强制关闭文件
pipeline流中至少有一个DN是正常的并且写入流没有被中断,则lease recovery就能够保证在恢复之后对client可见的数据不会丢失。这是因为:
- 在case1、2和3中有一个Replica是Finalized状态。则client在block构建过程中的stage1和或者stage3肯定已经挂了。这个算法不会移除任何数据。
- 在case4和5中,所有recovery的Replica都有RBW状态(all replicas to be recovered are in rbw state)。client肯定在block构建过程中的stage2时已经死去。假设recovery之前的pipeline有n个DN(DN0、DN1..DNn),DNi在4.a.ii返回的长度一定等于BRi。假设在pipeline中DN的一个子集DNs(Assume that a subset of the DataNodes S in the pipeline participates the length agreement),则长度为min(BRi, i为DNs中的索引)>=BRn-1>=BAn-1>=…>=BA0。这就保证了lease recovery不会移除已经对client可见的数据。
- 在case6中,这个算法没有任何保证,因为在recovery之前的pipeline中的所有DN都已经重启了。
Pipeline Set Up
pipeline setup的原因
- Create: 当一个新的block被创建时,pipeline需要在数据传输到DN之前被创建
- Append: 当一个文件需要追加时,并且最后一个block没有写满。由最后一个block的所有Replica所在的DN组成的pipeline需要在传输数据到DN之前被建立。
- Append Recovery: 当第2种情况失败时,包含剩下DN的pipeline需要被创建。
- Data Streaming Recovery: 如果Data Streaming失败,剩下DN组成的pipeline需要在Data Streaming resumes之前被建立。
- Close Recovery: 如果pipeline关闭失败,剩下的DN组成的pipeline为了finalize block而需要被建立。
pipeline setup 步骤
1、case2、3、4和5都是在已经存在的block上创建pipeline,因此block的GS需要随着pipeline的创建而更新。dfs client向NN请求一个新的GS。
2、dfs client向pipeline中的DN发送一个写block的请求,请求所带的参数有老版本GS的block id、block长度(Replica的长度一定大于等于此长度)、最大的Replica长度、flags、新的GS等。如下表所示:
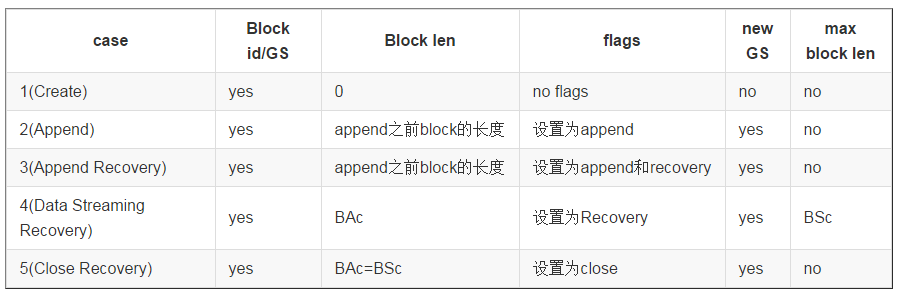
3、下表记录了DN在接收到pipeline setup请求之后的行为。需要注意的是,RWR Replica不参与pipeline recovery。通过对RWR Replica进行一些特殊的处理从而放宽这个限制。但是由于这种情况很少见,我们暂时选择什么也不做。
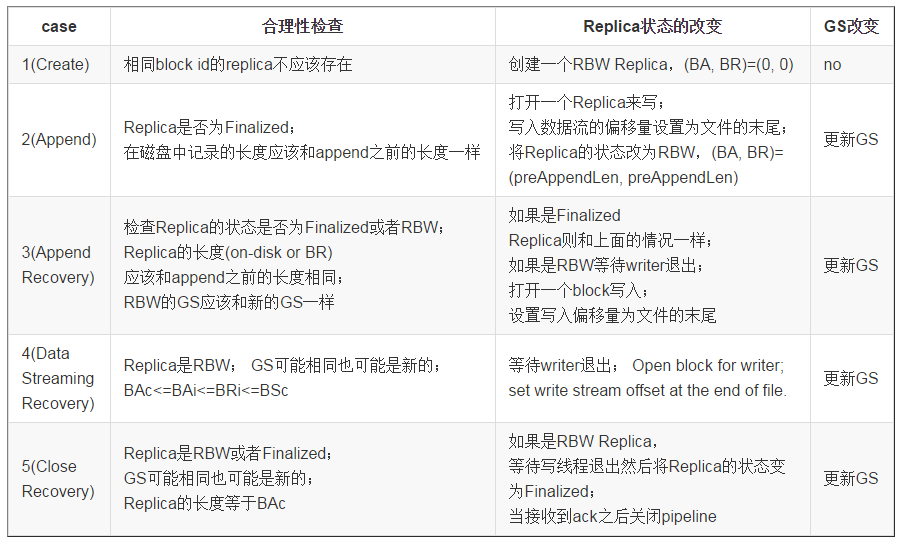
4、在case2、3和4中,当pipeline setup成功之后,dfs client将new GS、min length和新pipeline中的DN通知给NN。NN随后更新UnderConstruction block的GS、len和locations。
5、当pipeline创建失败时,如果pipeline中还有DN存活,则返回到第一步并且设置flags为recovery。如果pipeline中没有DN存活,表示此次pipeline失败。
如果user application在hflush或者write中blocked,则unblocked并抛出EmptyPipelineException。否则在下次write/hflush/close会得到EmptyPipelineException。
向NN报告Replica/Block状态、元数据信息
client reports
client通知NN更改UnderConstruction block的元数据信息或者状态。
在pipeline set up章节介绍的case2(append)、case3(append recovery)和case4(data streaming recovery)中,一个新的pipeline建立之后,client向NN汇报block的GS和pipeline中的DN。NN随后更新UnderConstruction block的GS、length和locations。
需要注意的是,假如pipeline是因为create block而建立的,则client不向NN汇报这个新的block和locations。相反当client通过addBlock/append申请一个新的block时,NN先将这个新block和locations放入blocksMap,然后将block和locations返回给client。这种设计有瑕疵。如果一个读请求去读最后一个block,而这个时间点正好发生在这个block在NN端放入blocksMap后,这个block的一个Replica在DN上创建之前,则这个读请求可能会得到”block dose not exit”的错。由于这种情况很少,我们有意的这样设计已换取性能。当新建block时,pipeline setup 之后,client没有必要向NN发送一个通知。
当client请求addBlock或者close文件时,NN会finalize最后一个block的GS和length。如果最后一个block已经存在一个与其GS/len相同的Replica,则将最后一个block的状态可能会变为Complete。否则将最后一个block的状态变为Committed。另外,如果最后一个block的Replica个数小于副本因子,则NN复制这个block使其达满足副本因子。
DataNode Reports
DN周期性的向NN汇报Replica的元数据信息或者状态的改变。当RBW Replica变为Finalized时向NN发送一个blockReceived信息。
Block Reports
- block汇报的内容包括两种,一种是针对Finalized Replica,另一种是针对RBW Replica。Finalized Replica时汇报的内容包括Finalized的Replica和之前状态是Finalized而现在是RUR状态的Replica。RBW Replica时汇报的内容包括RBW Replica、RWR Replicas和之前状态不是Finalized而现在的状态是RUR的Replica。*RBW Replica的长度是已经接收到的长度(BR)*。RWR的长度是一个负数。
- Replica汇报的状态是一个四元组(DataNode, blck_id, blck_GS, blck_len, isRbw)
- NN收到block report之后,和内存中的状态进行对比,对比的结果如下:(在内存中保存着4个list)
1、如果blck_id无效则放入deleteList中,例如blocksMap中不存在blck_id的Entry或者不属于任何一个文件
2、如果NN没有这个Replica(DataNode, blck_id)但是block report中有,则加入addStoredBlockList
3、如果NN有这个Replica(DataNode, blck_id)但是block report中没有,则加入rmStoredBlockList
4、如果Replica在NN中的状态是RBW,而block report中是Finalized,则加入updateStateList。(RBW应该是DN的状态,怎么会在NN中记录呢??)
避免client report和DataNode report竞争条件,则RBW Replica只加入deleteList或者addStoredBlockList。 - 添加一个新的Replica
1、Block在NN中的状态是Complete
当汇报的Replica的状态是Finalized时,如果它的GS和length和NN记录的值不一样,则将它加入blocksMap但要标记为corrupt。否则add the replica(??????)。
当汇报的Replica的状态是RBW时,如果这个文件已经关闭,如果Replica的GS/length和NN中记录的值不一样或者这个block已经达到了副本因子的个数,则命令它的DataNode将其Replica删除。否则do nothing。
2、Block在NN中的状态是Committed
这个处理的流程和上面的情况类似,除非汇报的Replica的状态是Finalized并且和NN中记录的GS和length相同,则NN将这个block的状态改为Complete。
3、Block在NN中的状态是UnderConstruction或者UnderRecovery
如果汇报的Replica的状态是Finalized并且此Replica的GS与NN中记录的GS相同或者比NN中记录的值新,则add the replica。同时标记这个replica为Finalized和保持对它的长度和GS的跟踪。
如果汇报的Replica的状态是RBW并且此Replica是有效的(GS不老,length不短),add the replica。如果Replica是RBW,则标记为RBW,否则标记为RWR。
否则忽略它(Otherwise ignore it)。 - 更新Replica的状态
当block report的内容是Replica从RBW变为Finalized状态时,
如果这个block是UnderConstruction状态,NN标记NN存储这个Replica为Finalized并且记录这个Finalized Replica的GS和length(NN marks the NN stored replica as finalized and keeps track of the finalized replica’s GS and length)。
如果这个block是Committed状态,如果这个Finalized Replica的GS和length和block的GS和length相匹配,则NN改变这个block的状态为Complete。
否则从NN上移除该Replica。
blockReceived
DataNode向NN发送blockReceived通知NN一个Replica已经完成。
当NN接收到blockReceived通知后,
如果(DataNode, blck_id)在NN中不存在,则add a new replica。
如果replica记录的状态是RBW,则更新replica的状态。
如果block是无效的,则要求DataNode删除这个replica。
Replica/Block State Transition
Replica State Transition
下图总结了Replica在DataNode上所有可能的状态转移。
- 新的Replica被创建
如果新的Replica是被client创建,则Replica的状态是RBW。
如果是由于NN发送的一个复制(复制副本或者balance)的指令,则Replica的状态是Temporary。 - 当DN重启时,RBW Replica改变状态为RWR。
- 当lease到期而引起的Replica recovery时,Replica的状态变为RUR
- 当client关闭文件、Replica recovery成功或者复制成功时,Replica的状态是Finalized。
- recovery发生错误,总是会更新Replica的GS
Block State Transition
下图总结了Block在NN上所有可能的状态转移。
- Block被创建
如果client调用addBlock给一个文件添加一个新的block时,创建Block
如果client调用append并且文件的最后一个block已经写满,则创建Block
新创建的Block的状态是UnderConstruction - 如果最后一个block没有写满,则append会将最后一个block由Complete状态变为UnderConstruction。
- 当addBlock或者close时,
最后一个Block的状态可能是Complete(Block的GS和len已经有Replica与之相匹配)也可能是Committed(不匹配则为Committed)。
addBlock会一直等到直到倒数第二个Block变为Complete。
直到最后两个block变为Complete时,文件才会关闭 - 当lease到期时,lease recovery将UnderConstruction状态的block变为UnderRecovery
block recovery会将UnderRecovery变为:
1、如果Replica的长度为0则移除。
2、如果recovery成功并且没有与GS和len相匹配的Finalized Replica存在,则变为Committed。
3、如果recovery成功并且有与GS和len相匹配的Finalized Replica存在,则变为Complete。
lease recovery会强制将Committed block变为Complete。 - Block的状态不会存储在磁盘。当NN重启时,未关闭文件的最后一个block变为UnderConstruction,*其余的block为Complete(倒数第二个block是Committed也会强制变为Complete)*。
如果这个block是文件的最后一个block,当NN重启时,最后一个block可能会从Complete或者Committed状态变为UnderConstruction。如果client依然存在,client会再次将此block finalize。否则当lease超期时,block recovery会再次finalize。 - 一旦一个block变成Complete或者Committed,该block的所有Replicas应该有相同的GS和长度。当一个block是UnderConstruction,它可能有多个版本的block混合存在集群中。
 wechat
wechat
